Blog moved to Umbraco v8

After 5 years of running an old version of Umbraco, my blog is finally migrated to v8 and the latest version of Articulate.…

Climbing the cliffs of web development, on .NET
After 5 years of running an old version of Umbraco, my blog is finally migrated to v8 and the latest version of Articulate.…
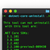
Uninstalling old versions of .NET Core used to be a tedious process, so much that I still had previews of 2.0 installed. But now it's super easy thanks to the newly released .NET Core Uninstall Tool. Have a look at how it works…
Adding MiniProfiler is an easy task, but documentation is a bit lacking. In 7 easy steps, I show how to install MiniProfiler on an empty ASP.NET MVC web application.…

In the context of my Ray Tracer Challenge, I wanted to run some performance analysis on my basic operations and data structures. For this installed and used BenchmarkDotNet, an OSS benchmarking tool used by Microsoft for performance testing the .NET Core runtime and class library. In this post, I'm going to share what I learned about this powerful tool.…
My latest ebook, ASP.NET Core Succinctly, written together with Ugo Lattanzi is been published and is available for free from Syncfusion.…

In this 4th post of the series, I implement the code to create images and save them to a file. And now I can see directly the trajectory of the projectile.…

After setting up the project, in this post I start implementing the code for the first chapter of the book, which focuses mostly on defining primitives (Point and Vectors), and vector algebra operations. And a simple ballistic problem to put all the operations in practice.…
Here it comes, the first post of my journey developing a Ray Tracer using .NET Core on a Mac, using only VS Code. In this first post I'll talk about the libraries and tools I decided to use, and how I setup the project structure using the `dotnet` CLI.…
It's now a few days after Codegarden, and after resting a bit, I can sit down, look back and draw some conclusions. And I think I might found a new family.…

I just bought the book "The Ray Tracer Challenge - A Test-Driven Guide to Your First 3D Renderer" and in the upcoming months, I'll be developing my own ray tracer, in .NET Core. I will also document my learning experience on the blog, for me, to keep track of my progress, and maybe discuss some implementation decisions with you, my readers, but also to share what I learn in the process.…